AI Training Dataset Market Size, Share, Trends, Growth, and Industry Analysis, By Type (Text, Image/Video and Audio), End-Use (IT, Government, Automotive, BFSI, Healthcare, Retail & E-commerce and others), and Region (North America, Europe, Asia-Pacific, Latin America, Middle-East and Africa) Regional Analysis and Forecast 2032.
Global AI Training Dataset market is predicted to reach approximately USD 7.51 billion by 2032, at a CAGR of 18.58% from 2024 to 2032.
AI training datasets are like the building blocks for AI systems. They help AI algorithms learn things like recognizing images, understanding language, and making predictions. As AI becomes more common in different areas like healthcare, finance, and retail, the need for good training datasets is also growing. This is because good datasets lead to better AI models, which can solve real-world problems more effectively.
In recent years, the Global AI Training Dataset Market has experienced significant growth, fuelled by the rapid advancement of AI technologies and the increasing adoption of AI solutions across industries. Organizations are increasingly recognizing the importance of high-quality training data in developing robust AI models that can deliver meaningful insights and drive business value. This has led to a surge in the availability of diverse and specialized datasets catering to specific use cases and applications.
Key players in the market include data providers, AI companies, research institutions, and technology giants, all of whom play crucial roles in curating, refining, and distributing training datasets. Additionally, the market is characterized by collaborations and partnerships between stakeholders to leverage their respective expertise and resources in addressing the growing demand for training data.
Global AI Training Dataset report scope and segmentation.
|
Report Attribute |
Details |
|
Estimated Market Value (2023) |
USD 1.62 Billion |
|
Projected Market Value (2032) |
USD 7.51 Billion |
|
Base Year |
2023 |
|
Forecast Years |
2024 – 2032 |
|
Scope of the Report |
Historical and Forecast Trends, Industry Drivers and Constraints, Historical and Forecast Market Analysis by Segment- Based on By Type, By End-Use, & Region. |
|
Segments Covered |
By Type, By End-Use, & By Region. |
|
Forecast Units |
Value (USD Million or Billion), and Volume (Units) |
|
Quantitative Units |
Revenue in USD million/billion and CAGR from 2024 to 2032. |
|
Regions Covered |
North America, Europe, Asia Pacific, Latin America, and Middle East & Africa. |
|
Countries Covered |
U.S., Canada, Mexico, U.K., Germany, France, Italy, Spain, China, India, Japan, South Korea, Brazil, Argentina, GCC Countries, and South Africa, among others. |
|
Report Coverage |
Market growth drivers, restraints, opportunities, Porter’s five forces analysis, PEST analysis, value chain analysis, regulatory landscape, market attractiveness analysis by segments and region, company market share analysis. |
|
Delivery Format |
Delivered as an attached PDF and Excel through email, according to the purchase option. |
Global AI Training Dataset dynamics
One of the key drivers is the increasing adoption of AI technologies across industries, leading to a growing demand for high-quality training data to develop and improve AI models. Additionally, advancements in AI algorithms and techniques, such as deep learning and reinforcement learning, are driving the need for larger and more diverse datasets to train complex models effectively.
Moreover, the proliferation of connected devices and the Internet of Things (IoT) is generating vast amounts of data, which can be leveraged to create valuable training datasets for AI applications. This influx of data from sources like sensors, mobile devices, and social media platforms presents opportunities for data providers and AI companies to capitalize on the growing market demand.
Despite the promise of AI, it faces obstacles like data privacy worries, biases in the information used to train AI models, and the need to label and annotate data. These challenges can limit the availability and quality of training data, which affects the creation and performance of AI models. To deal with these challenges, it's important for businesses and organizations to work together to create solid data management frameworks, ensure clear data practices, and include ethical concerns in the development of AI.
Global AI Training Dataset drivers
The increasing capabilities of AI, driven by advancements in techniques like deep learning and natural language processing, are creating a growing demand for high-quality training data. AI algorithms now handle increasingly complex tasks, requiring varied and specialized datasets for effective training. Additionally, evolving AI methods like transfer learning and federated learning necessitate datasets that encompass diverse scenarios and fields to optimize performance. This creates opportunities for data providers and AI companies to develop and offer curated datasets tailored to specific use cases and applications, thereby driving growth in the AI training dataset market.
The rise of AI in industries like healthcare, finance, retail, and cars has made training datasets a must-have. Businesses are using AI more and more to automate operations, make better decisions, and get useful information from huge amounts of data. So, there is a greater need for good training data to build AI models that can handle industry-specific problems and tasks. This trend is further accelerated by the emergence of new AI applications and use cases, such as predictive maintenance, personalized medicine, and autonomous vehicles, which require specialized datasets to train AI algorithms accurately.
Restraints:
Data privacy concerns are a key barrier to market growth for AI training datasets. As data collection and processing become more common, so does concern about data privacy and security. Organizations must follow strict laws like the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States, which control how personal data is collected, stored, and used. These regulations can restrict access to valuable datasets, limit data sharing and collaboration, and increase the cost and complexity of compliance, thereby hindering the availability and quality of training data for AI development.
AI training dataset quality is limited by biases and fairness issues. Datasets often reflect existing societal biases, leading to AI models that perpetuate unfairness and discrimination. These biases can stem from unbalanced data, incorrect labeling, or built-in preferences within algorithms. To overcome these issues, it is essential to carefully select and curate data, ensure diverse representation, and conduct thorough testing and validation. This helps identify and reduce biases, resulting in more accurate and fair AI models. However, achieving fairness and equity in datasets remains a complex and ongoing challenge, requiring collaboration between data scientists, domain experts, and ethicists to develop unbiased AI models that promote fairness, transparency, and accountability.
Opportunities:
The proliferation of Internet of Things (IoT) devices and connected sensors is generating vast amounts of data, which can be leveraged to create valuable training datasets for AI applications. IoT devices collect data from various sources, such as environmental sensors, wearable devices, and industrial equipment, providing real-time insights into physical environments and processes. This influx of data presents opportunities for data providers and AI companies to capitalize on the growing market demand for IoT-generated datasets. By curating and analysing IoT data, stakeholders can develop specialized datasets for predictive maintenance, smart city solutions, and industrial automation, among other applications, driving growth in the AI training dataset market.
Segment Overview
The AI training dataset market is categorized into three main segments based on the type of data: text, image/video, and audio. Text datasets include textual information such as documents, articles, and social media posts, which are used for natural language processing tasks like sentiment analysis, chatbots, and language translation. Image and video datasets comprise visual data such as photos, videos, and satellite imagery, which are essential for computer vision applications like object detection, facial recognition, and autonomous vehicles. Audio datasets consist of sound recordings, speech samples, and audio files, which are utilized for speech recognition, voice assistants, and audio analysis tasks. Each type of dataset plays a critical role in training AI models across a wide range of applications, driving innovation and advancements in AI technology.
The AI training dataset market is segmented by end-use industries, encompassing IT, automotive, government, healthcare, BFSI (banking, financial services, and insurance), retail & e-commerce, and others. In the IT sector, training datasets are utilized for developing AI-powered software, applications, and platforms, enabling tasks such as data analysis, recommendation systems, and virtual assistants.
The automotive industry leverages training datasets for developing autonomous driving systems, driver assistance technologies, and vehicle diagnostics, enhancing safety and efficiency on the roads. Government agencies utilize training datasets for various applications, including public safety, urban planning, and disaster response, leveraging AI technologies to improve citizen services and governance.
In the healthcare sector, training datasets are used for medical imaging analysis, disease diagnosis, drug discovery, and personalized medicine, contributing to advancements in healthcare delivery and patient outcomes. BFSI organizations employ training datasets for fraud detection, risk assessment, customer service automation, and algorithmic trading, enhancing operational efficiency and decision-making in financial services. Retail & e-commerce companies utilize training datasets for customer behaviour analysis, inventory management, demand forecasting, and personalized marketing, driving customer engagement and sales.
Global AI Training Dataset Overview by Region
North America leads the AI market, primarily due to the strong presence of tech giants, AI companies, and research institutions in the United States. Advanced infrastructure, cutting-edge technologies, and supportive government policies drive innovation and development in the region. Europe is another major market, fuelled by significant investments in AI, strict data protection laws, and widespread adoption across various industries.
The Asia Pacific region is experiencing rapid growth, fuelled by emerging economies like China, India, and Japan investing heavily in AI infrastructure, talent development, and innovation ecosystems. Additionally, government initiatives, rising tech start-ups, and a burgeoning digital economy contribute to the market expansion in the region. Latin America and the Middle East & Africa regions are witnessing increasing adoption of AI technologies, albeit at a slower pace compared to other regions. Factors such as growing awareness, improving infrastructure, and strategic partnerships with global players are driving market growth in these regions. However, challenges related to data privacy, infrastructure limitations, and talent shortages remain significant barriers to widespread adoption.
Global AI Training Dataset market competitive landscape
Established players such as Google, Microsoft, IBM, Amazon, and Facebook dominate the market with their vast resources, proprietary datasets, and advanced AI capabilities. These companies offer comprehensive AI solutions, cloud platforms, and AI-as-a-service offerings, leveraging their extensive datasets and AI algorithms to address diverse industry needs. Additionally, niche players and start-ups are emerging, specializing in specific verticals, applications, or types of training data. These players often focus on data curation, labeling, and annotation services, catering to niche markets or addressing specific challenges such as bias mitigation or data privacy. Collaboration and partnerships between industry stakeholders are prevalent, with companies forming strategic alliances to enhance their dataset offerings, expand market reach, and accelerate AI innovation. Moreover, mergers and acquisitions are common in the market as companies seek to consolidate their positions, acquire specialized expertise, and gain access to proprietary datasets and technologies.
Global AI Training Dataset Recent Developments
Scope of global AI Training Dataset report
Global AI Training Dataset report segmentation
|
ATTRIBUTE |
DETAILS |
|
By Type |
|
|
By End-Use |
|
|
By Geography |
|
|
Customization Scope |
|
|
Pricing |
|
Objectives of the Study
The objectives of the study are summarized in 5 stages. They are as mentioned below:
Research Methodology
Our research methodology has always been the key differentiating reason which sets us apart in comparison from the competing organizations in the industry. Our organization believes in consistency along with quality and establishing a new level with every new report we generate; our methods are acclaimed and the data/information inside the report is coveted. Our research methodology involves a combination of primary and secondary research methods. Data procurement is one of the most extensive stages in our research process. Our organization helps in assisting the clients to find the opportunities by examining the market across the globe coupled with providing economic statistics for each and every region. The reports generated and published are based on primary & secondary research. In secondary research, we gather data for global Market through white papers, case studies, blogs, reference customers, news, articles, press releases, white papers, and research studies. We also have our paid data applications which includes hoovers, Bloomberg business week, Avention, and others.

Data Collection
Data collection is the process of gathering, measuring, and analyzing accurate and relevant data from a variety of sources to analyze market and forecast trends. Raw market data is obtained on a broad front. Data is continuously extracted and filtered to ensure only validated and authenticated sources are considered. Data is mined from a varied host of sources including secondary and primary sources.
Primary Research
After the secondary research process, we initiate the primary research phase in which we interact with companies operating within the market space. We interact with related industries to understand the factors that can drive or hamper a market. Exhaustive primary interviews are conducted. Various sources from both the supply and demand sides are interviewed to obtain qualitative and quantitative information for a report which includes suppliers, product providers, domain experts, CEOs, vice presidents, marketing & sales directors, Type & innovation directors, and related key executives from various key companies to ensure a holistic and unbiased picture of the market.
Secondary Research
A secondary research process is conducted to identify and collect information useful for the extensive, technical, market-oriented, and comprehensive study of the market. Secondary sources include published market studies, competitive information, white papers, analyst reports, government agencies, industry and trade associations, media sources, chambers of commerce, newsletters, trade publications, magazines, Bloomberg BusinessWeek, Factiva, D&B, annual reports, company house documents, investor presentations, articles, journals, blogs, and SEC filings of companies, newspapers, and so on. We have assigned weights to these parameters and quantified their market impacts using the weighted average analysis to derive the expected market growth rate.
Top-Down Approach & Bottom-Up Approach
In the top – down approach, the Global Batteries for Solar Energy Storage Market was further divided into various segments on the basis of the percentage share of each segment. This approach helped in arriving at the market size of each segment globally. The segments market size was further broken down in the regional market size of each segment and sub-segments. The sub-segments were further broken down to country level market. The market size arrived using this approach was then crosschecked with the market size arrived by using bottom-up approach.
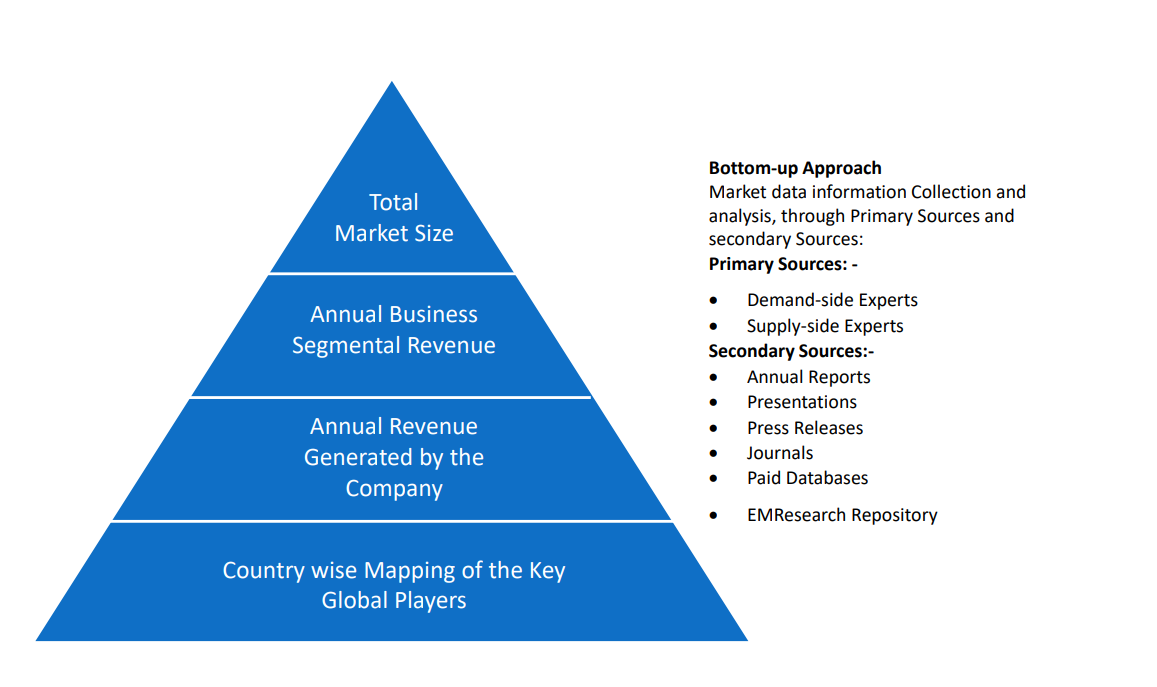
In the bottom-up approach, we arrived at the country market size by identifying the revenues and market shares of the key market players. The country market sizes then were added up to arrive at regional market size of the decorated apparel, which eventually added up to arrive at global market size.
This is one of the most reliable methods as the information is directly obtained from the key players in the market and is based on the primary interviews from the key opinion leaders associated with the firms considered in the research. Furthermore, the data obtained from the company sources and the primary respondents was validated through secondary sources including government publications and Bloomberg.
Market Analysis & size Estimation
Post the data mining stage, we gather our findings and analyze them, filtering out relevant insights. These are evaluated across research teams and industry experts. All this data is collected and evaluated by our analysts. The key players in the industry or markets are identified through extensive primary and secondary research. All percentage share splits, and breakdowns have been determined using secondary sources and verified through primary sources. The market size, in terms of value and volume, is determined through primary and secondary research processes, and forecasting models including the time series model, econometric model, judgmental forecasting model, the Delphi method, among Flywheel Energy Storage. Gathered information for market analysis, competitive landscape, growth trends, product development, and pricing trends is fed into the model and analyzed simultaneously.
Quality Checking & Final Review
The analysis done by the research team is further reviewed to check for the accuracy of the data provided to ensure the clients’ requirements. This approach provides essential checks and balances which facilitate the production of quality data. This Type of revision was done in two phases for the authenticity of the data and negligible errors in the report. After quality checking, the report is reviewed to look after the presentation, Type and to recheck if all the requirements of the clients were addressed.

